👋 Hi, this is Gergely with a subscriber-only issue of the Pragmatic Engineer Newsletter. In every issue, I cover challenges at Big Tech and startups through the lens of engineering managers and senior engineers. If you’ve been forwarded this email, you can subscribe here.
Q: I’ve joined a new company and a few months in, it’s clear my team would be better off if we adopted some best practices which are currently missing. But how can I introduce these without treading on too many toes?
If you’ve changed companies, you’ve probably found yourself in a position of observing gaps that your new team has, and how using one or two ‘best practices’ would benefit everyone. These could be to do with matters like planning or development, testing approaches, rollout strategies and more. In this issue, we cover this area in depth:
“Best practices” vs “practices”. Making the case that “best” is less important for these practices.
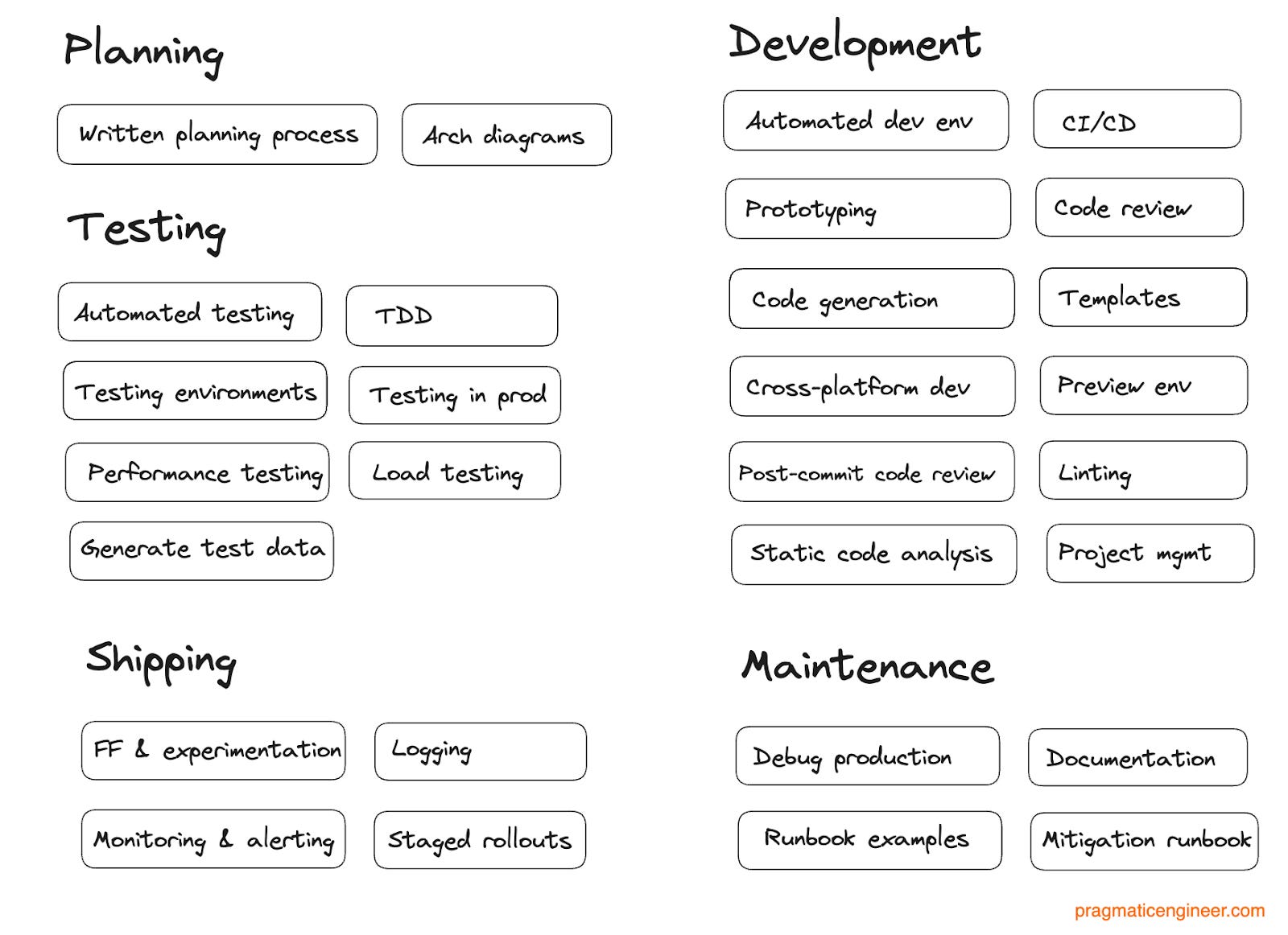
Common software engineering practices. For planning, development, testing and maintenance.
Two questions before adopting an engineering practice. What is the problem to be solved, what would the effect be?
Adopting a practice at team level. Most common approaches.
Risk of copy/pasting practices. There’s good reason to be skeptical about practices just because they worked well at other places.
Rejecting and dropping practices. Just because you introduced a practice doesn’t mean it should be permanently adopted.
Encouraging engineers to consider practices, as a manager. Empowering software engineers to bring practices that help the team work better.
We previously touched on related topics in these articles:
As a software engineer, you’ve undoubtedly heard the term “best practice.” It’s an approach or process that’s understood to help build software that’s superior in terms of speed of execution, shipping with higher quality, or building more maintainable code.
However, workplaces are different enough that what’s considered as “best practice” at one place, might fail at another.
Take a conventional best practice of doing code reviews before merging a pull request to the codebase. Code reviews have lots of upsides: catching errors, spreading knowledge, and getting feedback sooner from peers. But the biggest downside is it delays the development process by pausing it for the code review. And some tooling needs to be put in place for a review. Still, at most places the downsides aren’t big compared to the upsides.
But sometimes code reviews don’t make sense, for example in a one-person project when a code review is impractical. Likewise, when building a throwaway prototype there’s no point in a review. And there are teams with experienced software engineers for which a different approach works much better: post-commit reviews, where code reviews are done after the code is merged. This is because teams which work well together tend to get more value from not breaking the workflow of other engineers, and the number of issues which code reviews detect is low enough to justify not adding a delay to merging code.
If “best practice” code reviews are not necessarily always the optimal approach, then what about other “best practices” which are also contextual? Instead of “best practices”, I call them ‘software engineering practices.’ There are tried-and-tested software engineering practices that help with one or more dimensions of the software engineering process.
Written planning process. Before starting to code non-trivial projects, a plan is written and circulated for feedback. This plan might be called a Request for Comment (RFC,) an Engineering Requirements Document (EDD,) a Design Doc, or Architectural Decision Record (ADR.) We covered more on these in the issue Engineering planning with RFCs, Design Documents and ADRs
Standardized approach to architectural diagrams. Agreeing on the tooling or approach for creating architectural diagrams, including which symbols and approaches are not understood by some members of the group, or new joiners.
Development
Automated setting up of a new development environment. When starting at a new company or moving to a new project, it often takes painfully long to get set up in the development environment. Installing all the tools, setting the environment variables, and doing things like initializing a local database, all take time. Cloud-based developments like GitPod turn this process into a simple click. We covered GitPod’s product roadmap here. Simon Will writes: “I’ve seen developers lose hours a week to issues with the development environment. Eliminating that across a large team is the equivalent of hiring several new full-time engineers!”
Prototyping. Iterating quickly by building throwaway prototypes to validate ideas and get quick feedback from customers.
Code reviews. Before committing code, other engineers review and sign it off.
Automated code formatting. Engineers often like to format their code in different ways, and a difference in how many spaces to use for indentation, or using tabs instead, can turn into an argument and reduce the readability of the code. You can use automated code formatting solutions at the IDE-level, or solve the issue with linting.
Linting. This is the automated checking of code for stylistic and other errors which can be checked with rules. Putting linting in place before creating a pull request can help ensure the code is formatted the same way. You can also add more advanced rules such as codifying some architecture rules, for example specifying that a View class should not directly reference a Model class.
Static code analysis. Run more advanced code checks before committing, such as searching for security vulnerabilities or detecting features to be deprecated.
Templates for new projects or components. Provide ready-to-clone repository setups with the expected folder structure, and a README in place. Do the same for commonly-used components.
Code generation for common components. When following an opinionated architecture during development, speed up code writing with tooling which generates the boilerplate code to wire things up. For example, this is an approach we took at Uber in using a code generator to output modules for our RIBs native mobile architecture.
Automated preview environments. Simon Willison writes: “Reviewing a pull request is a lot easier if you can actually try out the changes. The best way to do this is with automated preview environments, directly linked to from the pull request itself. Vercel, Netlify, Render and Heroku all have features that can do this.”
Post-commit code reviews. Code reviews are done only after the commits are made. This approach typically increases iteration speed, while still having some code reviews in place. As a tradeoff, more regressions might reach production. This practice usually works best with very small or highly experienced teams.
Cross-platform development approaches. When building a product for several platforms – say, the web, iOS, Android and desktop – an alternative is to use a framework which allows for sharing most of the code across all platforms. This could be an off-the-shelf framework, although there’s always the temptation to create something that perfectly fits your use case.
Continuous integration (CI) and continuous deployment (CD). Automatically running tests on all code changes (CI) and running the full test suite and deploying changes when committing code (CD).
Project management approaches. Using approaches like Kanban, Scrum and other frameworks like SaFE (Scaled Agile Framework,) LeSS (Large-Scale Scrum,) or your own approach. We covered more on this in How Big Tech runs tech projects and Software engineers leading projects.
Testing
Automated testing. Writing unit, integration, end to end, performance, load, or other types of tests. This approach usually increases quality and maintainability and often results in less time overall to ship software, thanks to regressions being flagged quickly.
Test-driven development. A subset of automated testing where tests are written before the actual code is.
Testing environments. Shipping code to intermediary environments for more testing, Instead of shipping straight to production. The upside is increased confidence that the code is correct. The downsides are it takes longer to ship things to production and there’s extra work maintaining the testing environments.
Testing in production, and doing it safely.Instead of using testing environments, shipping to production and using safe methods for tests, you could utilize processes like tenancies, feature flags or staged rollouts.
Testing with production data. It can be useful to be able to test with production data, without affecting production. Some companies build more sophisticated systems that can “fork” production traffic to a developer machine, and the developer can execute.
Load testing. Simulating high load for backend systems, to prepare for situations where production loads spikes and to test which systems might get overloaded or break.
Performance benchmarking and testing. For applications where performance is important, benchmark things like resource usage, i.e., CPU load, responsiveness and latency. This is important for products of which high performance is expected. An additional practice is automating performance testing and performance benchmarking to catch performance regressions right at the code changes which introduce them.
Generating test data. It can be useful to have ways of bulk-generating test data that mirrors production usage. Simon Willison has written more about this in Mechanisms for creating test data.
Feature flags and experimentation. Control the rollout of a change by hiding it behind a feature flag in the code. This feature flag can then be enabled for a subset of users, and those users execute the new version of the code. This approach can also be used to run A/B tests to ensure that the feature performs in-line with expectations (or that it does not cause measurable regressions in.)
Staged rollouts, also referred to as ‘progressive delivery.’Instead of releasing new features to customers all at once, release them in stages and gather feedback. Another flavor of this is ‘blue-green deploys’ that Stripe also uses and we covered in detail.
Monitoring and alerting. Tracking a system’s health signals and alerting oncall engineers if something unusual happens.
Logging. Recording information on the system to help with debugging later.
Debugging production. Having ways to inspect the system as it runs, or to play back production use-cases, and also methods for inspecting variables and code paths to discover what the issue could be.
Documentation. Deciding what to document and how, tooling, whether documentation will be kept up to date and how to do this.
Runbook templates. For teams which are oncall, runbooks that can help the oncall engineer resolve a specific type of alert, are very helpful. Having runbook examples and templates available helps to keep these runbooks consistent and easy to navigate.
3. Two questions before adopting an engineering practice
When starting at a new workplace, it’s tempting to introduce practices that worked well in your previous role. There can be a similar urge after reading about a practice which worked somewhere else, which you think would greatly benefit your new team.
However, before deciding to make a case for adopting a practice, I suggest taking a step back and asking two questions:
Question #1: What is the problem to be solved?
A simple question, but one I’ve observed engineers often neglect before starting to put a new practice in place. Be clear what the current issues are.
For engineering practices, problems worth solving can include:
Developers spend too much time doing X. Can we speed this up? X could mean waiting on scripts or code reviews, setting up development environments, writing tests, or more.
The quality of our output isn’t good and needs improving. There might be too many bugs, too many outage incidents.
The speed of execution is slow. Getting simple things done could take longer than necessary due to continuous processes, tools, or workarounds.
Developers context switch too much. Context switching for the wrong reasons.
It’s hard to do X. It could be hard and time-consuming to debug a part of the system, to resolve certain types of outages, or to get people on the same page. It’s ideal if you can verbalize the consequences of things being hard to do.
Once you’ve verbalized the problem, what is its impact? If it was solved or made less of an issue, what would improve? Things that teams – and companies – tend to care about include:
Revenue generation
Business goals
Regressions
Reliability
Outages
Iteration speed
And how pressing is the issue? For example, if it’s hard to debug one of the services, but that service is barely touched and only needs debugging once every few months, then perhaps it’s not urgent to solve it.
Question #2: If adopted, what would be the effect of a practice?
When there’s a problem to solve, wait before moving ahead with the engineering practice that helps with it. That’s because every new practice introduced will have an impact on how people and teams work.
For example, say your team has no code reviews in place and also there are quality issues, like too many bugs being shipped. By putting mandatory, pre-merge code reviews in place, those quality issues could be reduced. However, now there will be new issues, such as people having to wait on code reviews, figuring out what to do when no reviewers are available, or what to do when there’s a lot of debate about a code review which stalls the process.
There are a few common ways to find out what may happen if a practice is put in place:
Do a “pre-mortem.” Make hypotheses about how things can change. You know your team, your company, and the people. Imagine you put this practice in place: what issues could it cause? For example, you might know there’s a team member who’s outspoken about a practice you want to bring in, which could be a source of conflict if not done right. If your team has less experienced engineers and you are proposing a practice which will make the development workflow more complex – like suggesting a certain architecture pattern to follow – then they’ll need more hand-holding and may struggle to follow the approach without support.
Consult case studies of the new practice being introduced elsewhere. There are plenty of teams and companies which are open to sharing their experiences with practices and how they worked. Check out engineering blogs, conference talks and recordings to gather details on how things went at other companies. However, be aware that engineers often focus more on success stories and less on what went wrong when acting as company representatives.
Talk with people who already use this practice. The problem with case studies is they tend to give an overly rosy picture of a practice. To get the full picture, it helps to talk to engineers who have used the practice, ideally in a similar environment to yours. If you can find colleagues who adopted the practice, also talk with them. If you can’t access people internally, don’t be afraid to reach out externally to engineers who have written about using this practice. For example, when I was at Skyscanner, a few engineers reached out to Spotify to learn more about how engineering teams organized there. A few Skyscanner engineers even traveled to Stockholm to meet and discuss it with Spotify engineers, who were very helpful. And it all started with just a cold email to an engineer!
4. Adopting a practice at team level...
Subscribe to The Pragmatic Engineer to unlock the rest.
Become a paying subscriber of The Pragmatic Engineer to get access to this post and other subscriber-only content.